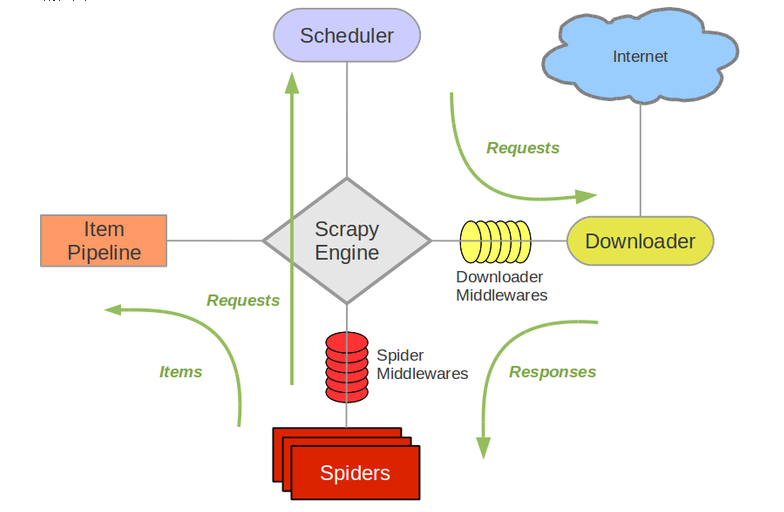
写在前面 1、本篇架构介绍内容为笔记性质(其实就是从很多博客东找西找复制粘贴来的),后续具体实现再写自己针对这个项目的内容。因为架构介绍属于备忘录性质的,且之前已经用requests库完成过一些针对部分网站的特异性爬虫,所以scrapy的介绍不如看完以后直接转载别人的(废话这么多主要为了解释自己为什么犯懒不想在第一篇自己写)。具体参考过的博文原地址在最后。2、工作中需要对某网站(对,不能说哪个)的公告类信息进行及时爬取,并对公告内容的重要信息结构化后在数据库中存储,故开此坑。至于为什么一个硬件工程师会开爬虫的坑主要…

