写在前面
1、本篇架构介绍内容为笔记性质(其实就是从很多博客东找西找复制粘贴来的),后续具体实现再写自己针对这个项目的内容。因为架构介绍属于备忘录性质的,且之前已经用requests库完成过一些针对部分网站的特异性爬虫,所以scrapy的介绍不如看完以后直接转载别人的(废话这么多主要为了解释自己为什么犯懒不想在第一篇自己写)。具体参考过的博文原地址在最后。
2、工作中需要对某网站(对,不能说哪个)的公告类信息进行及时爬取,并对公告内容的重要信息结构化后在数据库中存储,故开此坑。至于为什么一个硬件工程师会开爬虫的坑主要是因为不务正业业务需要,项目的主要目的是从爬虫这个角度熟悉一下软件方面的知识,尤其是前端和数据库的。
1.Scrapy框架介绍
写一个爬虫,需要做很多的事情。比如:发送网络请求、数据解析、数据存储、反反爬虫机制(更换ip代理、设置请求头等)、异步请求等。这些工作如果每次都要自己从零开始写的话,比较浪费时间。因此Scrapy把一些基础的东西封装好了,在他上面写爬虫可以变的更加的高效(爬取效率和开发效率)。因此真正在公司里,一些上了量的爬虫,都是使用Scrapy框架来解决。
2.Scrapy架构图
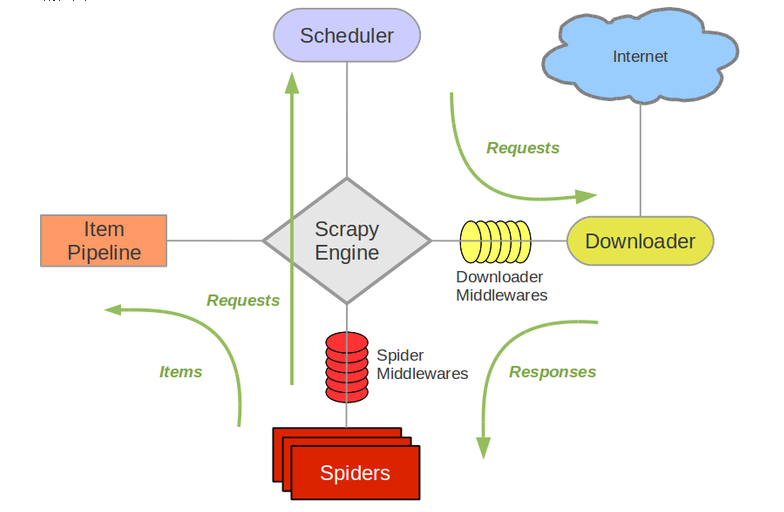
3.Scrapy框架模块功能
- Scrapy Engine(引擎):Scrapy框架的核心部分。负责在Spider和ItemPipeline、Downloader、Scheduler中间通信、传递数据等。
- Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面中的哪些数据是我们需要的,都是由程序员自己决定。
- Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。
- Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。
- Item Pipeline(管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。
- Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。
- Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间通信功能的中间件。
4、Scrapy运行流程
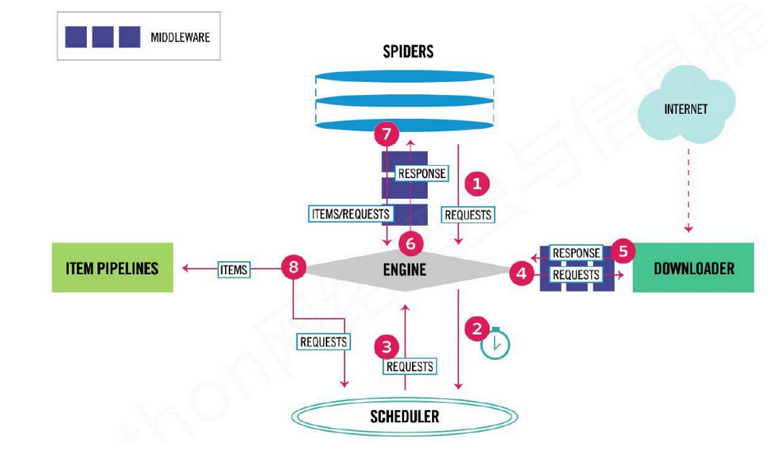
主要步骤(流程图2):
1.Spiders(自己书写的爬虫逻辑,处理url及网页等【spider genspider -t 指定模板 爬虫文件名 域名】),返回Requests给engine——>
2.engine拿到requests返回给scheduler(什么也没做)——>
3.然后scheduler会生成一个requests交给engine(url调度器)——>
4.engine通过downloader的middleware一层一层过滤然后将requests交给downloader——>
5.downloader下载完成后又通过middleware过滤将response返回给engine——>
6.engine拿到response之后将response通过spiders的middleware过滤后返回给spider,然后spider做一些处理(如返回items或requests)——>
7.spiders将处理后得到的一些items和requests通过中间件过滤返回给engine——>
8.engine判断返回的是items或requests,如果是items就直接返回给item pipelines,如果是requests就将requests返回给scheduler(和第二步一样)
5、源码简介
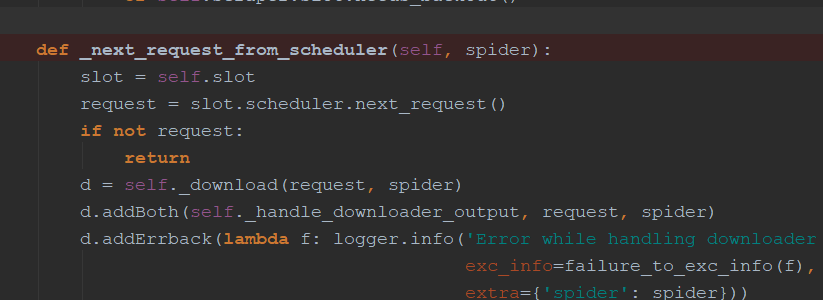
engine.py中介绍:通过_next_request_from_scheduler判断是否有requests(request返回给engine直接返回给scheduler【第一步】),request会首先调用schedule()函数发送给schedule(第二步),然后返回给engine
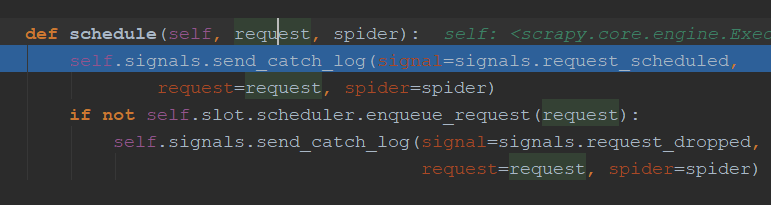
5.1 downloader简介
5.2 Request和Response简介:
|
1 2 3 4 5 6 |
class Request(object_ref): def __init__(self, url, callback=None, method='GET', headers=None, body=None, cookies=None, meta=None, encoding='utf-8', priority=0, dont_filter=False, errback=None, flags=None): ...... |
官网介绍(具体官网网址:https://doc.scrapy.org/en/latest/topics/request-response.html):
参 数:
- url(字符串) - 此请求的URL
- callback(callable) - 将使用此请求的响应(一旦下载)调用的函数作为其第一个参数。有关更多信息,请参阅下面将其他数据传递给回调函数。如果请求未指定回调,则将使用spider的
parse()方法。请注意,如果在处理期间引发异常,则会调用errback。 - method(string) - 此请求的HTTP方法。默认为
'GET'。 - meta(dict) -
Request.meta属性的初始值。如果给定,则此参数中传递的dict将被浅层复制。 - body(str 或unicode) - 请求体。如果a
unicode被传递,则str使用传递的编码(默认为utf-8)对其 进行编码。如果body未给出,则存储空字符串。无论此参数的类型如何,存储的最终值都是str(从不unicode或None)。 - headers(dict) - 此请求的标头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。如果
None作为值传递,则根本不会发送HTTP标头。 - cookies(字典或清单) -请求cookie。这些可以以两种形式发送。
- 使用词典:request_with_cookies = Request(url="http://www.example.com", cookies={'currency': 'USD', 'country': 'UY'})
- 使用dicts列表:request_with_cookies = Request(url="http://www.example.com", cookies=[{'name': 'currency', 'value': 'USD', 'domain': 'example.com', 'path': '/currency'}])后一种形式允许自定义 cookie的属性
domain和path属性。这仅在保存cookie以供以后请求时才有用。当某个站点返回cookie(在响应中)时,这些cookie存储在该域的cookie中,并将在将来的请求中再次发送。这是任何常规Web浏览器的典型行为。但是,如果由于某种原因,您希望避免与现有Cookie合并,则可以通过将dont_merge_cookies密钥设置为True 来指示Scrapy执行此操作Request.meta。不合并cookie的请求示例:request_with_cookies = Request(url="http://www.example.com", cookies={'currency': 'USD', 'country': 'UY'}, meta={'dont_merge_cookies': True})
- encoding(字符串) - 此请求的编码(默认为
'utf-8')。此编码将用于对URL进行百分比编码并将正文转换为str(如果给定unicode)。 - priority(int) - 此请求的优先级(默认为
0)。调度程序使用优先级来定义用于处理请求的顺序。具有更高优先级值的请求将更早执行。允许使用负值以指示相对较低的优先级。 - dont_filter(boolean) - 表示调度程序不应过滤此请求。当您想要多次执行相同的请求时,可以使用此选项来忽略重复过滤器。小心使用它,否则您将进入爬行循环。默认为
False。 - errback(callable) - 在处理请求时引发任何异常时将调用的函数。这包括因404 HTTP错误而失败的页面等。它接收Twisted Failure实例作为第一个参数。有关更多信息,请参阅下面的使用errbacks捕获请求处理中的异常。
- flags(list) - 发送给请求的标志,可用于日志记录或类似目的。
|
1 2 3 4 5 6 7 8 9 10 |
class Response(object_ref): def __init__(self, url, status=200, headers=None, body=b'', flags=None, request=None): self.headers = Headers(headers or {}) self.status = int(status) self._set_body(body) self._set_url(url) self.request = request self.flags = [] if flags is None else list(flags) ...... |
参数:
- url(字符串) - 此响应的URL
- status(整数) - 响应的HTTP状态。默认为
200。 - headers(dict) - 此响应的标头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。
- body(字节) - 响应主体。要将解码后的文本作为str(Python 2中的unicode)访问,您可以使用
response.text来自编码感知的 Response子类,例如TextResponse。 - flags(列表) - 是包含
Response.flags属性初始值的列表 。如果给定,列表将被浅层复制。 - request(
Requestobject) -Response.request属性的初始值。这表示Request生成此响应的内容。
参考资料:
1. Apollo. scrapy架构简介. https://www.cnblogs.com/apollo1616/p/10427116.html
2. biu嘟. scrapy架构简介. https://www.cnblogs.com/lyq-biu/p/9745974.html

文章评论